
关于java爬虫以及一些实例
首先是工具介绍
Jsoup
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
HttpClient
HTTP 协议可能是现在 Internet 上使用得最多、最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资源。虽然在 JDK 的 java net包中已经提供了访问 HTTP 协议的基本功能,但是对于大部分应用程序来说,JDK 库本身提供的功能还不够丰富和灵活。HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
可能看的有点迷,直接上例子就好了
首先我们要确定一个要爬取的网站拿一个都快被爬破的经典教材起点中文网的完美世界吧
https://www.qidian.com/search?kw=%E5%AE%8C%E7%BE%8E%E4%B8%96%E7%95%8C
然后我们要对这个网页的结构进行分析,按F12
找到书的名字和作者名字的具体在哪个div里面,或者可以直接根据class名字找到要爬取的内容
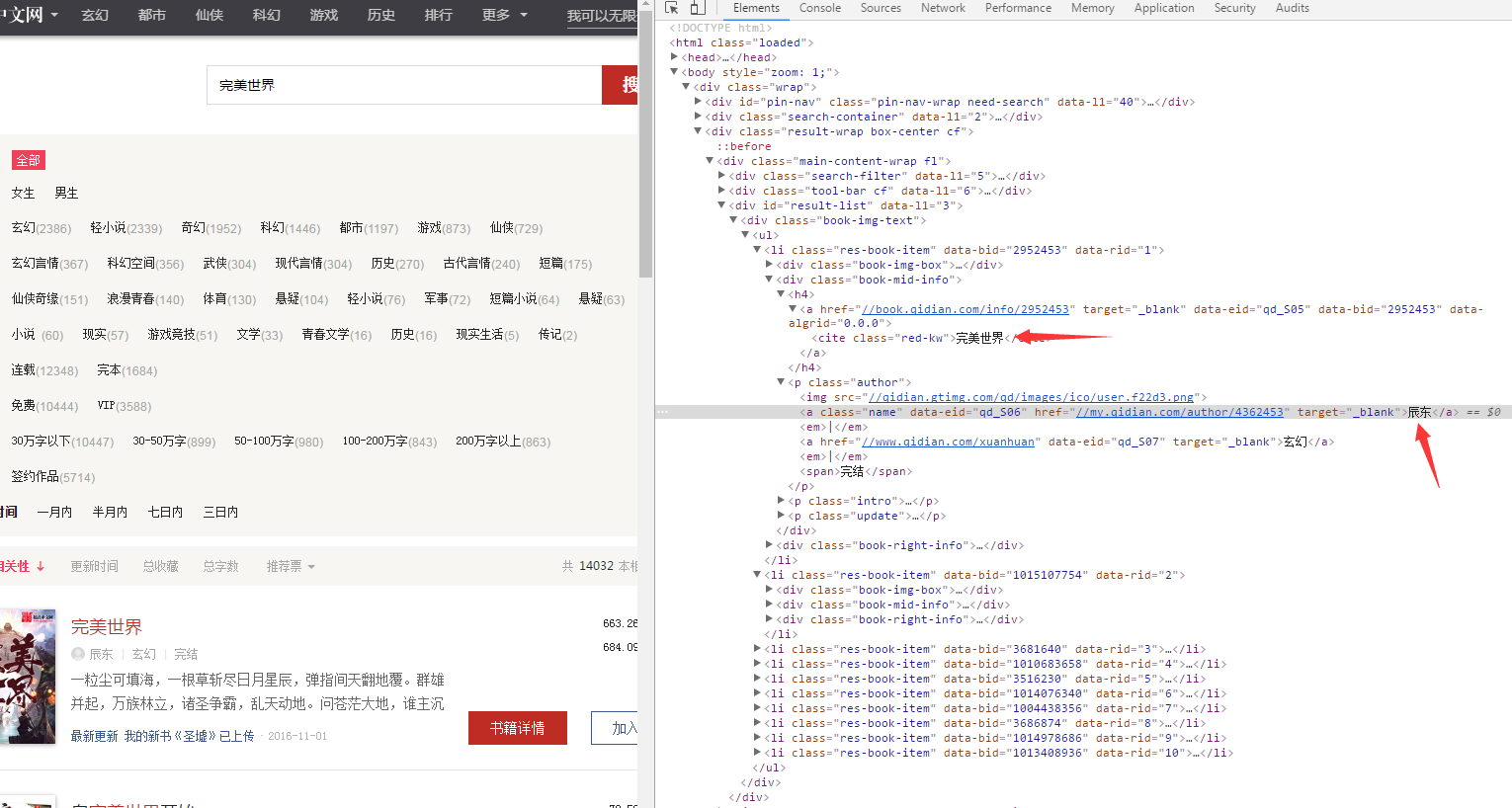
下面具体看代码解释
package com.wpb.dao;
import java.io.IOException;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.wpb.bean.Book;
public class test {
public static void main(String[] args) throws IOException {
//要爬取的网站
String url = "https://www.qidian.com/search?kw=完美世界";
//获得一个和网站的链接,注意是Jsoup的connect
Connection connect = Jsoup.connect(url);
//获得该网站的Document对象
Document document = connect.get();
int cnt = 1;
//我们可以通过对Document对象的select方法获得具体的文本内容
//下面的意思是获得.bool-img-text这个类下的 ul 下的 li
Elements rootselect = document.select(".book-img-text ul li");
for(Element ele : rootselect){
//然后获得a标签里面具体的内容
Elements novelname = ele.select(".book-mid-info h4 a");
String name = novelname.text();
Elements author = ele.select(".book-mid-info p a");
String authorname = author.first().text();
Elements sumadvice = ele.select(".total p");
String sum = sumadvice.last().text();
System.out.println("书名:"+name+" 作者:"+authorname+" 推荐量:"+sum);
}
}
}
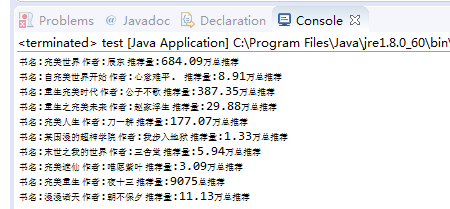
上面的一个例子差不多是Jsoup的一个简单应用
下面来个Httpclient的简单应用,我觉得这个就是简单地模拟一下浏览器访问这样的形式获取信息
网站是这个
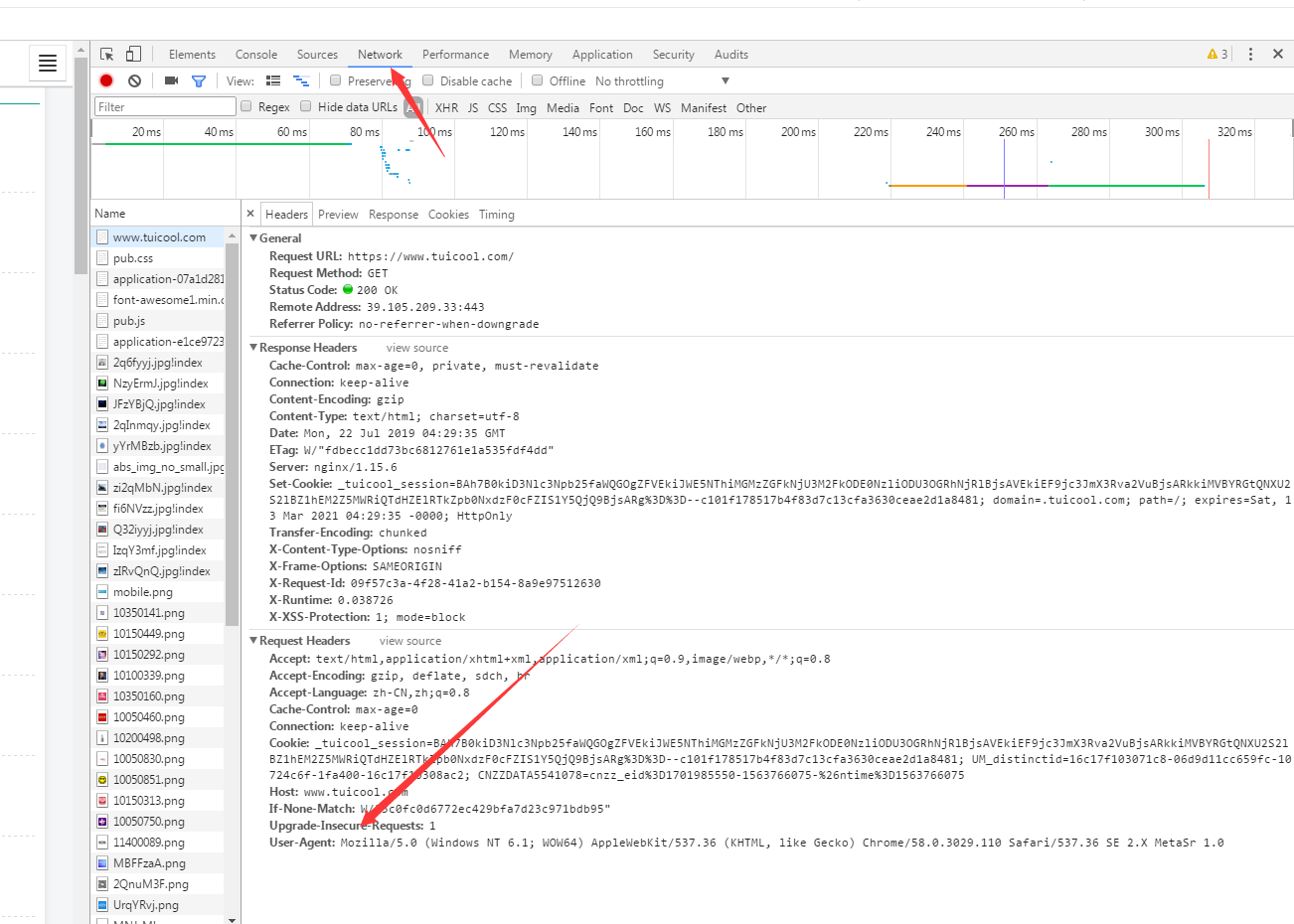
那么既然是模拟浏览器访问,就要设置Header来给人家网站说明一些信息
依然是F12然后点network,按F5找一个User-agent
package com.wpb.service;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class httpUtilUse {
public static void main(String[] args) throws ClientProtocolException, IOException {
String URL = "https://www.tuicool.com/";
//创建模拟一个客户端
CloseableHttpClient client = HttpClients.createDefault();
//创建一个网站的连接对象
HttpGet httpGet = new HttpGet(URL);
//设置一些Header信息,说是从哪个浏览器访问的
httpGet.setHeader("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0");
//让客户端开始访问这个网站
CloseableHttpResponse response = client.execute(httpGet);
//获取到了该网站页面的html
HttpEntity entity = response.getEntity();
//把html转化成String
String html = EntityUtils.toString(entity);
System.out.println(html);
System.out.println("successful");
}
}
通过这个httpclient我们可以进行一些其他的骚操作
比如下载个图片啥的
package com.wpb.service;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
public class getImage {
public static void main(String[] args) throws ClientProtocolException, IOException {
String imgUrl = "http://aimg0.tuicool.com/EzQVN3u.jpg";
CloseableHttpClient client = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(imgUrl);
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0");
CloseableHttpResponse response = client.execute(httpGet);
HttpEntity entity = response.getEntity();
//判断获取的信息的类型是什么样婶的
String fileType = entity.getContentType().getValue();
//如果这个是image型的
if(fileType.contains("image")){
//获取这个东西的字节流
InputStream inputStream = entity.getContent();
//直接把他输入到一个路径中
FileUtils.copyInputStreamToFile(inputStream, new File("d://test.jpeg"));
}
response.close();
client.close();
System.out.println("successful");
}
}
把Jsoup和javaIO流结合一下就可以爬取一些你想要的东西了
比如下载一些hdu的问题
package com.wpb.service;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class downLoadText {
public static void main(String[] args) throws IOException {
String s1 = "http://acm.hdu.edu.cn/showproblem.php?pid=";
BufferedWriter bw = new BufferedWriter(new FileWriter("C:"+File.separator+"hdu.txt"));
//循环访问多个问题
for(int i = 1000; i<= 1099; i++){
String s2 = s1 + i;
System.out.println(s2);
Connection connection = Jsoup.connect(s2);
Document document = connection.get();
bw.write("Problem");
bw.newLine();
Elements problem = document.select(".panel_content");
for(Element ele : problem){
String p = ele.text();
System.out.println(p);
bw.write(p);
bw.newLine();
}
}
bw.flush();
bw.close();
}
}
还有还有 比如爬取我老婆照片
package com.wpb.service;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class getManyImag {
public static int cnt = 1;
public static void main(String[] args) throws IOException {
//分析网页的变化,发现每变化一个网页,url里面就加30
for (int i = 30; i <= 2010; i += 30) {
add("http://movie.douban.com/celebrity/1018562/photos/?type=C&start=" + i
+ "&sortby=like&size=a&subtype=a");
}
}
public static void add(String url) throws IOException {
//获取链接
Connection conn = Jsoup.connect(url);
//获取这个页面内容
Document document = conn.get();
//使用Jsoup获取具体内容
Elements ele = document.select(".cover a img");
//模拟一个浏览器用户
CloseableHttpClient client = HttpClients.createDefault();
for (Element e : ele) {
//通过Jsoup获取图片的url,我们要获取这个图片的url才能再通过httpclient下载下来
String imgurl = e.attr("src");
//设置一个连接对象
HttpGet httpGet = new HttpGet(imgurl);
//设置header
httpGet.setHeader("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36");
//httpclient进行连接
CloseableHttpResponse response = client.execute(httpGet);
//获取内容
HttpEntity entity = response.getEntity();
//将内容转化成IO流
InputStream content = entity.getContent();
//写入
FileUtils.copyInputStreamToFile(content, new File("c://tu//wpb" + cnt + ".jpg"));
cnt++;
}
System.out.println("successful");
}
}
如需转载,请注明文章出处和来源网址:http://www.divcss5.com/html/h57028.shtml






